
Using ColdFusion to read OpenGraph and Twitter Metadata
Fun with meta
Honestly, John Krasinski was ahead of the curve when he started his web series, Some Good News. Which got me thinking that there really is not a place to find good news. Reading through the feed on any given day and you can easily understand why Facebook decided to pay out $52 million dollars to its moderators as compensation for mental health issues.
I thought it might be a fun little exercise to create a page where I could enter a URL, use cfhttp to read the meta data from the page, and have a tiled display of all the articles. I will be using ColdBox to get up to speed quickly and since this will not be a production application it may not have a lot of polish, but it will work. Once the application has been scaffolded it is time for the fun stuff. It is definitely possible to grab the page contents and try to pull the meta tags out with regex, but I will be using the cbjsoup module. The first step is to get it installed by dropping to the command line and install with box install cbjsoup. That done, lets get the spider service written.
component {
// SpiderService.cfc
property name="jSoup" inject="javaLoader:org.jsoup.Jsoup";
function spider( required string linkUrl ){
var meta = {};
cfhttp( url = linkUrl );
var jsDoc = jSoup.parse( cfhttp.fileContent );
var el = jsDoc.select( "meta" );
var filtered = el.filter( function( its ){
return its.attr( "name" ).find( "twitter:" ) ||
its.attr( "name" ).find( "og:" ) ||
its.attr( "property" ).find( "twitter:" ) ||
its.attr( "property" ).find( "og:" );
} );
filtered.each( function( i ){
len( i.attr( "name" ) ) ? meta[ i.attr( "name" ) ] = i.attr( "content" ) : meta[ i.attr( "property" ) ] = i.attr( "content" );
} );
return meta;
}
}
The service itself is simple and contains only one method, spider, which takes an URL as a parameter. Using cfhttp I read in the contents of the web page, use jSoup to filter the meta tags, and filter the meta tags that have either twitter: or og: as part of the name or property attribute. Finally the keys that were found are compiled and returned as a structure.
Next it is time to configure the ColdBox handlers that will call the SpiderService. The first handler I created is spider that will call the service and just dump the values out on the screen which can be useful for debugging. Next is the feed handler that will handle the tiled display of stories.
component extends="coldbox.system.EventHandler" {
property name="SpiderService" inject="model";
function index (event, rc, prc) {
event.setView('demos/index');
}
function spider (event, rc, prc) {
prc['url'] = event.getValue("url", "");
prc['data'] = {};
if (prc.url.len()) {
prc.data.append(SpiderService.spider(linkUrl = prc.url));
}
event.setView('demos/spider');
}
function feed (event, rc, prc) {
if(!application.keyExists("feed")) application['feed'] = [];
prc['feed'] = [];
prc['url'] = event.getValue("url", "");
if (prc.url.len()) {
var meta = SpiderService.spider(linkUrl = prc.url);
var tmp = {
'title': site.keyExists("twitter:title") ? meta['twitter:title'] : meta['og:title'],
'description': site.keyExists("twitter:description") ? meta['twitter:description'] : meta['og:description'],
'image': site.keyExists("twitter:img:src") ? meta['twitter:img:src'] : meta['og:image'],
'url': site.keyExists("twitter:url") ? meta['twitter:url'] : meta['og:url']
};
var exists = application.feed.filter(function(i){
return i.url == tmp.url;
}).len() ? true : false;
if(!exists) application.feed.append(tmp);
}
prc.feed.append(application.feed, true);
event.setView('demos/feed');
}
}

The spider handler is really simple; it makes a call to the spider service and will dump any meta data it finds for the url, if any.
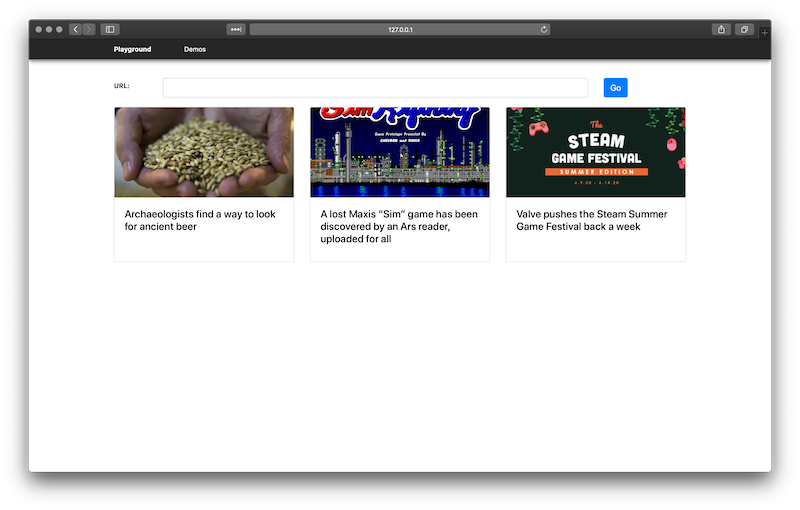
The feed handler builds off the spider handler. The results from the spider service are saved in the meta structure. Next a temporary structure stores the four main values needed for the tiled screen: title, description, image, and url. This code prefers to use the twitter meta if it exists, if not, fall back to the opengraph site. Finally check to see if the item already exists in the application's feed array to prevent duplicate items.
Originally I was going to add this feature to a website I was working on, but that has fallen by the wayside. Still, I thought someone might find it interesting. If you would like to follow along at home the link to the repo is below, just follow the instructions in the readme.
Enjoy!